How They Work
LSM Tree
sequential writes
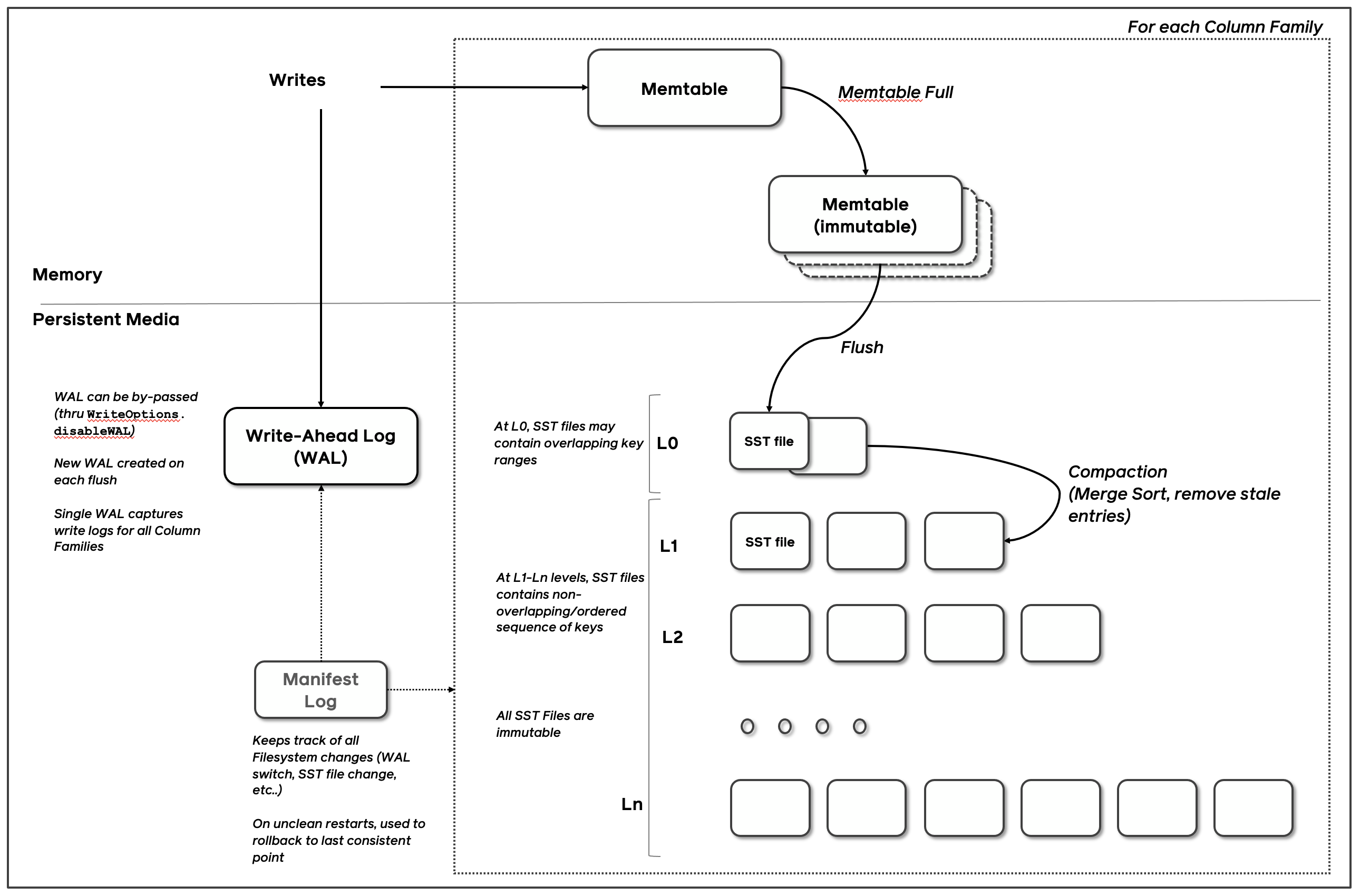
-
Write Process:
- New data is first written to an in-memory buffer called MemTable.
- When MemTable reaches a size threshold, it's flushed to disk as an immutable SST (Sorted String Table) file.
- Periodically, multiple SST files are merged and sorted in a process called compaction.
-
Read Process:
- Reads check the MemTable first.
- If not found, it checks the most recent SST files, then proceeds through older SSTs.
- Bloom filters are often used to quickly determine which SSTs might contain the data.
-
Levels:
- Data is organized into multiple levels, with each level containing larger and less frequently updated data.
- Lower levels (closer to memory) are smaller and more frequently updated.
B+ Tree
-
Structure:
- Balanced tree with a root, internal nodes, and leaf nodes.
- Internal nodes contain keys and pointers to child nodes.
- Leaf nodes contain keys and either data or pointers to data.
- Leaf nodes are typically linked for efficient range queries.
-
Write Process:
- Tree is traversed from root to appropriate leaf.
- If leaf has space, data is inserted.
- If leaf is full, it splits into two nodes, and the split propagates up the tree if necessary.
-
Read Process:
- Tree is traversed from root to leaf, using keys to guide the search.
- Once the leaf is reached, data can be retrieved directly or via a pointer.
Performance Characteristics Explained
LSM Tree
-
Excellent Write Performance (O(1) amortized):
- Why: Writes are initially to in-memory MemTable, which is very fast.
- Flushing to disk happens in large sequential writes, which are efficient.
- Amortized O(1) because occasional larger operations (flushes and compactions) are spread over many writes.
-
Good but Potentially Degrading Read Performance (O(log N) worst case):
- Why: May need to check multiple SST files, increasing with the number of levels.
- Bloom filters help, but their effectiveness decreases as data size grows.
- Worst case occurs when data is in the oldest/largest SST level.
-
High Space Efficiency:
- Why: Compaction process merges and removes obsolete data.
- Sequential storage in SSTs allows for better compression.
-
Write Amplification:
- Why: Data may be rewritten multiple times during compaction.
- Each level typically involves rewriting the entire level's worth of data.
-
Read Amplification:
- Why: Might need to check multiple SST files for a single read.
- Can be mitigated by caching and Bloom filters, but still present.
B+ Tree
random writes
-
Good Write Performance (O(log N)):
- Why: Needs to traverse the tree for each write, hence logarithmic.
- Splits and rebalances can cause additional writes, but are infrequent.
-
Excellent Read Performance (O(log N)):
- Why: Tree structure allows efficient traversal to locate data.
- Height of the tree grows logarithmically with the amount of data.
- Once leaf level is reached, data access is direct and fast.
-
Moderate Space Efficiency:
- Why: Maintains structure for fast access, which uses some extra space.
- Internal nodes contain only keys and pointers, saving some space.
- Can have some internal fragmentation due to partially filled nodes.
-
Lower Write Amplification (compared to LSM):
- Why: Updates are often in-place or require minimal restructuring.
- No equivalent to the LSM compaction process.
-
Minimal Read Amplification:
- Why: Each read operation typically only traverses the tree once.
- No need to check multiple files or structures for a single read.
Use Case Suitability
LSM Tree
- Ideal for write-heavy workloads due to fast initial writes.
- Good for scenarios with high insert rates but less frequent updates or deletes.
- Suitable for time-series data, log data, and some types of analytical workloads.
B+ Tree
- Well-suited for workloads with a mix of reads and writes.
- Excellent for scenarios requiring frequent range queries.
- Ideal for transactional workloads in traditional relational databases.
https://planetscale.com/blog/btrees-and-database-indexes
https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
https://www.reddit.com/r/databasedevelopment/comments/187cp1g/comment/kbdv6j2/